با پیشرفت فناوری اطلاعات و توسعه اینترنت در دهههای اخیر شاهد این بودهایم که حجم زیادی از اطلاعات کامپیوتری ایجاد شدهاند، با پردازش این اطلاعات امکان مدلسازی و پیشبینی رویدادهای آینده بوجود آمده است. از طرفی دیگر با رشد اکوسیستم اینترنت اشیا و تجهیزات هوشمند شاهد تولید حجم عظیمی از دادههایی هستیم که توسط ماشینآلات تولید میشوند. برای استفاده از این اطلاعات باید به پردازش کلان دادهها یا همان Big Data بپردازیم.
کلان دادهها چیست؟
کلان دادهها یا همان دادههای حجیم(Big Data) به دادههایی گفته میشود که دارای حجمی فراتر از دادههای معمولی در ذخیرهسازی، انتقال، پردازش و محاسبات میباشند.

جهان امروز ما در دادهها غرق شده است و اگر نتوانیم از دادهها به درستی استفاده کنیم با چالشهای زیادی مواجه خواهیم شد. دادهها میتوانند به راحتی کیفیت زندگی انسانها را بهبود ببخشند و صرفهجویی زیادی را در منابع و هزینهها برای ما به همراه بیاورند.
برای این که بتوانیم از دادههای کلان به خوبی بهره ببریم باید از فناوریهای پردازشی استفاده کنیم که توانایی پوشش دادن ویژگیهای چنین دادههایی را داشته باشند.
ویژگیهای مهم کلان دادهها
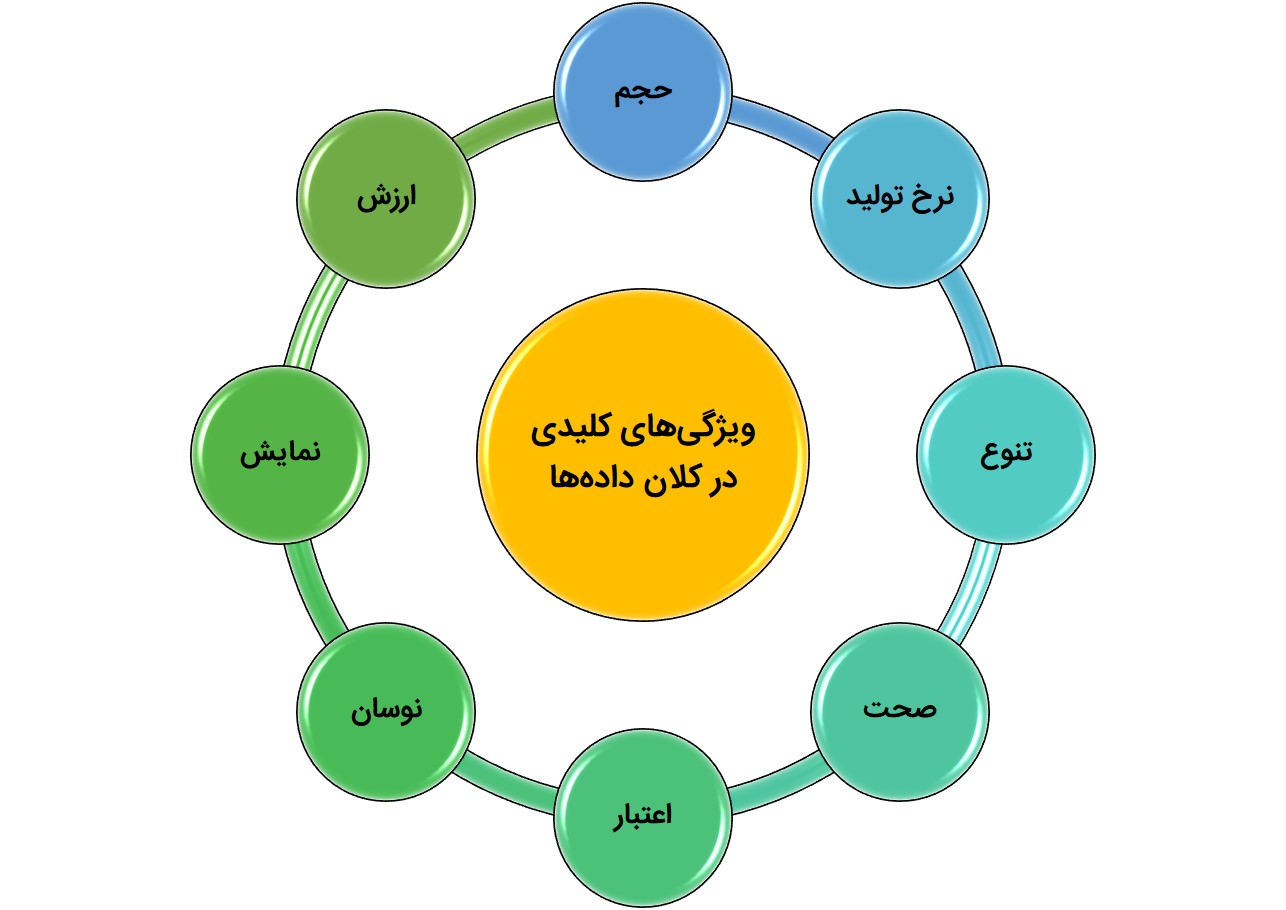
کلان دادهها دارای ۸ ویژگی کلیدی هستند که اگر بتوانیم بر این ویژگیها تسلط داشته باشیم امکان استفاده حداکثری از ظرفیت موجود در دادهها را خواهیم داشت. این ویژگیها که به ۸V معروف هستند، عبارتند از:
۱- حجم داده(volume)
حجم دادههای امروزی به صورت یک تابع نمایی در حال افزایش است. وجود شبکههای اجتماعی، اینترنت اشیا، ماشینهای هوشمند، وب جهان شمول، تصاویر ماهوارهای و تراکنشهای گسترده مالی باعث شده تا شاهد رشد شدید در حجم دادهها باشیم.
این حجم عظیم از داده نیاز به روشهای خاصی در ذخیرهسازی، پردازش، استخراج اطلاعات، مدلسازی، امنیت و انتقال داده دارند.
۲- نرخ تولید(Velocity)
دادههای امروزی با سرعت بالایی تولید میشوند. استفاده از این دادهها زمانی ارزشمند خواهد بود که بتوانیم به صورت بلادرنگ از آنها استفاده کنیم.
۳- تنوع(Velocity)
دادههایی که در بیگ دیتا با آنها سر و کار داریم از منابع مختلفی گردآوری میشوند. بنابراین باید این دادهها را همگونسازی کنیم، دادههای نویزدار را حذف کنیم و تجمیع دادهها را مدنظر قرار دهیم تا احتمال خطا در دادهها به حداقل کاهش یابد و پایگاهدادهها از یک جامعیت بالایی برخوردار شوند.
۴- صحت(Veracity)
اعتماد به دادهها با توجه به این که از منابع مختلفی جمعآوری میشوند کار پیچیدهای است. اینجا هستش که دادهکاوی، متنکاوی، و وبکاوی وارد عرصه میشوند تا صحت دادهها را بسنجند و آنها را قابل استفاده کنند.
۵- اعتبار(Validity)
هر دادهای را نمیتوان در هر جایگاهی استفاده کرد. درک این موضوع که آیا دادهها برای یک کاربرد جدید هم اعتبار دارند از اهمیت ویژهای برخوردار است.
۶- نوسان(Volatility)
ماهیت و مقادیر داده در کلاندادهها به سرعت تغییر میکند. به همین دلیل تعیین دامنه تغییرات دادهای یک کار پیچیده است. برخی از تغییرات باعث میشود تا دادههای قبلی دیگر ارزشمند نباشند. بنابراین باید در الگوریتمهای یادگیری که از دادههای حجیم به شکل گستردهای استفاده میکنند این موضوع مدنظر قرار گیرد.
۷- نمایش(Visualization)
درک دادهها و نمایش آنها یکی از چالشهای عمده در Big Data میباشد. این که بتوانیم دادهها را در قالب نمودارها و اینفوگرافها مدلسازی کنیم بسیار مهم است زیرا که درک انسانی از دادهها در بسیاری از کاربردها اهمیت دارد.
۸-ارزش(Value)
در دادههای حجیم موازنهی بین هزینه ومنفعت حائز اهمیت زیادی است. ما برای ذخیرهسازی دادهها در اَبرها (یا مهها)نیاز به یک هزینه بالا داریم. این در حالی است که در برخی از موارد منافع حاصله برای ما ارزش چندانی را ایجاد نمیکند. ارزشگذاری دادهها و پیداکردن کاربرد برای آنها در رشد فناوری بیگ دیتا موثر میباشد.
مدیریت دادههای حجیم

دادهها قدرت ایجاد میکنند زیرا که میتوان از آنها اطلاعات استخراج کرد و اطلاعات به ما دانش و خرد نسبت به موضوعات مختلف میدهد. امّا باید توجه داشت که اگر بر روی دادهها مدیریتی صورت نپذیرد، دادهها مانند سیلی عظیم ما را در خود غوطهور خواهند کرد.
برای مدیریت دادهها باید به سه بخش کلیدی زیر توجه داشت:
- ذخیرهسازی
- پردازش
- تحلیل دادههای حجیم
دادههایی که در Big Data با آنها سر و کار داریم بدون ساختار هستند. تا چندسال پیش معمولا دادههای ما در دیتابیسهای سنتی ذخیره میشدند. ولی در دادههای حجیم ما ناچار هستیم دادهها را برروی محیط اَبرهای محلی(Local Cloud) و به صورت فشرده ذخیره کنیم.
در واقع دادههای آینده از مدل NoSQL بهره میبرند که یک مدل غیررابطهای میباشد. این پایگاه دادهها سندمحور و گرافمحور هستند و قابلیتهای بیشتری را برای مقیاسپذیری دارند. به همین دلیل عملکرد بهتری را از خود بروز میدهند.
هادوپ و بیگ دیتا

Hadoop یک فریمورک برای پردازش، ذخیره و تحلیل دادههای عظیم میباشد. این فریمورک براساس عملکرد موتورهای جستجو بوجود آمده و کار اصلی آن ایندکس کردن صفحات وب بود.
در هادوپ دادههای حجیم خوشهبندی(Cluster) میشوند و در شبکه توزیع میشوند تا بر روی آنها پردازش صورت گیرد. برای اطمینان بیشتر از عملکرد چنین سیستمی، اسناد بر روی چندین کامپیوتر توزیع میشوند تا در صورت بروز هرگونه خطایی امکان بازیابی اطلاعات وجود داشته باشد.
هادوپ یک مشکل بزرگ دارد و آن هم این است که از امکان پردازش بلادرنگ پشتیبانی نمیکند. جمعآوری اطلاعات از گرههای مختلف یک زمان چندثانیهای را میگیرد که یک چالش اساسی محسوب میشود. هرچند که توسعهدهندگان Hadoop قول دادهاند در نسخههای بعدی این پلتفرم این مشکل را تا حدود زیادی برطرف کنند.
نقش کلاندادهها بر زندگی هوشمند
کلان دادهها یا همان دادههای حجیم از موضوعات ترند(داغ) در حوزه فناوری اطلاعات میباشد که در سالیان اخیر توجه محققان بسیاری را به خود جلب کرده است. بیگدیتا میتواند در علوم پزشکی، مالی و بانکداری، ورزش، تحقیقات، مدیریت انرژی، صنعت خودرو، شهرهای هوشمند، یادگیری ماشین، بازاریابی، رسانههای اجتماعی، خردهفروشی و دادههای مکانمحور مورد استفاده قرار گیرد.
با کمک دادههای کلان میتوان روال زندگی روزمره و کسب و کارها را بهبود بخشید. نکته مهم در مورد دادههای حجیم این است که امکان استفاده از آنها توسط تمامی افراد یک جامعه مقدّور میباشد و این استفاده همگانی از اطلاعات باعث بهبود نرخ بهرهوری در سطح کلان میشود.
چند کاربرد خاص دادههای حجیم
- کشف تقلب در حوزههای مختلف
- مبارزه با پولشویی و اختلاسهای مالی
- پایش وضعیت شبکههای ارتباطی و پیشبینی خرابی آنها
- تشخیص رفتارهای غیرمتعارف در شبکهها
- امکان پیشبینی رفتار مشتریان و مصرفکنندگان
- تحلیل دقیق بازارهای مالی و سایر بازارها(کاربرد در بورس)
- امکان طراحی محصولات جدید با توجه به نیاز بازار
- امکان افزایش رضایت مشتریان و بهبود تجربه کاربری
- استفاده از دادههای مکان محور برای کاربردهای گوناگون
- توسعه علوم داده(Data Science) و پیشرفت تحقیقات در حوزههای مختلف
- بهبود مدیریت ارتباط با مشتریان
- قیمتگذاری صحیح کالا با توجه به سیگنالهای دریافتی از بازار یا رقبا